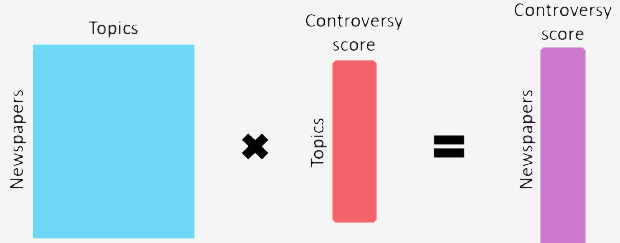
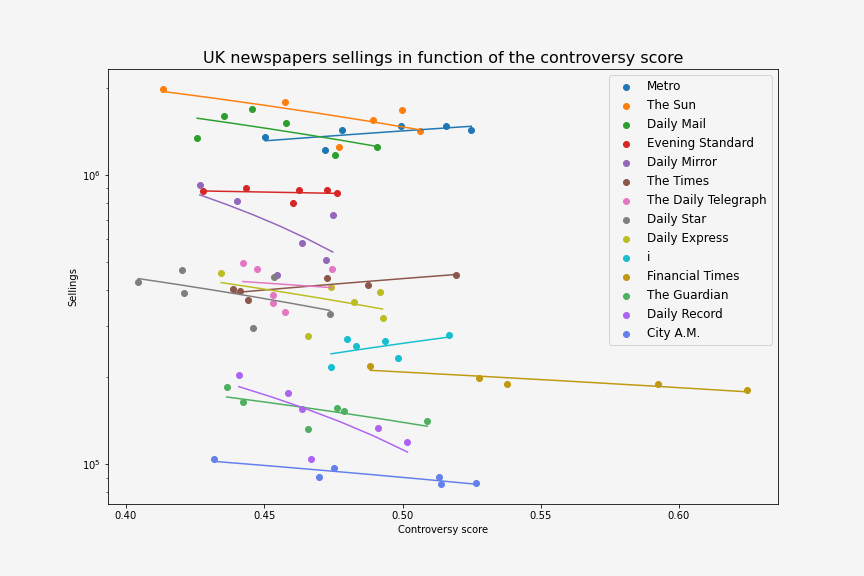
Which topics to study?
The first step of our analysis is to extract relevant topics from the corpus. In fact, since we have to deal with Natural Language Processing (NLP), it is necessary to first preprocess the dataset. Therefore, the quotations need to be cleaned in order to get only their essence, i.e. words that represent the theme addressed by the speaker.
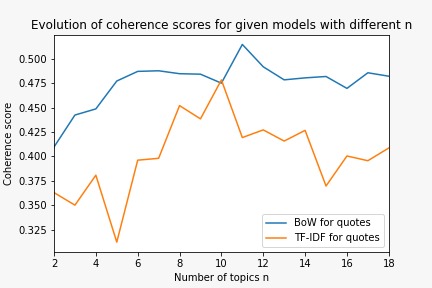
To carry this out, a Latent Dirichlet Allocation (LDA) model can be used either on the most frequent words through bag-of-words (BoW) model or on the most relevant words using the term frequency–inverse document frequency (TF-IDF) method.
A coherence score can be computed for each list of words in order to quantify how good the two methods are compared to each other. The LDA model then allows to separate the corpus into \(n\) different topics. By running it with different values of \(n\), as it is shown in the figure, we can see that there is an optimal number of topics.
This number can then be kept for further computations.
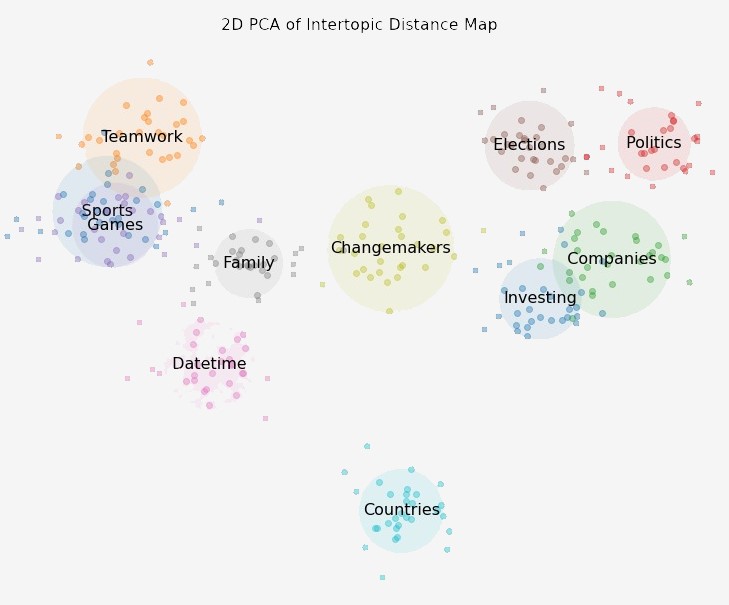
By fixing the number of topics, the LDA model can then be used to extract the most relevant terms for each topic.
Next, a word which represents best each topic was chosen by using the list of most relevant terms in each topic. This resulted in the right-hand side graphic, with visual representation of the cluster (i.e. topic) formed by those words.
It can be noted that by mapping the intertopic distance we can visually see how close two topics are to each other.
You can play with an interactive version of the figure below, which shows the top 10 most relevant words for each topic. By selecting a topic number, the probability to encounter its top 10 associated words in the corpus is given along with an estimate of the number of times they are linked to the topic.
For the rest of our analysis we can choose those words to form a set of sub-topics that allows to have more meaningful representation of each topic.
The following table summarizes the chosen topics and their associated number:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Topic | Sports | Teamwork | Companies | Politics | Games | Elections | Datetime | Family | Changemakers | Countries | Investing |